How to Run HEP-SPEC06 Benchmark
Table of Contents:
- Requirements
- Run rules
- Parallel runs
- 32-bit binaries
- Before you start
- The runspec.sh run script
- Manually installing the SPEC CPU2006 benchmark suite and running the HS06
- Unlock the system under test when you have finished
- CPU type
- HS06
- Clock speed (MHz)
- L2 cache size (KB)
- Cores (runs)
- Memory (GB)
- Mainboard type
- Script to automatize the system disclosure
- Adding results to WIKI
- Why don’t you just use the results from spec.org?
- Ok, but isn’t there a conversion factor between spec.org numbers and HS06?
- Why do you use those compilation flags? We could get more performance with other flags.
- If your OS is 64 bit, why do you run 32-bit binaries?
- Why do you use “multiple speed” instead of speed or rate?
- Why do you use “all_cpp” instead of SPECint or SPECfp?
- Why don’t you just write your own benchmark suite?
Requirements
Before you run the benchmarks, check this list of requirements:
Benchmark
HS06 is based on the SPEC® CPU2006 benchmark suite. The SPEC benchmarks are available from www.spec.org. The license is a site license, i.e. the original and copies thereof may be used (only) by anyone within the same corporate structure, if purchased by a corporation. The complete license agreement form is coming with the benchmark media package.
SPEC recommends to use the latest release of the benchmark (V1.2 as of September 2011).
Operating system
The WLCG CPU benchmarking rules require to run the CPU performance benchmark in the same operating environment which is provided by the site.
The current default operating system is either RHEL or one of its clones (CentOS, Scientific Linux, Scientific Linux CERN, …).
To run the benchmarks on a bare machine, install the x86_64 flavour of one of these operating systems, without changes to kernel parameters, updated drivers, and so on.
Compiler
The aim of this benchmarking procedure is to measure the CPU performance of a particular worker node in the same operating environment which is used in production mode at your site. It is therefore required to use the GNU Compiler Collection (GCC) coming with the operating system.
Other compilers, e.g. from vendors like Intel, Pathscale, or PGI, as well as special performance libraries, are not permitted in order to run the HS06 benchmark!
Compiler flags
The mandatory set of compiler flags is provided by the LCG Architects Forum:
-O2 -pthread -fPIC -m32
Configuration files and script
Configuration files and a run script are available as a gzipped tar archive spec2k6-2.24.tar.gz, MD5=a42e12acbc1ef533b3c1328b77c14b01}).
Run rules
Parallel runs
The standard way of running the HS06 is to run as many benchmarks in parallel as there are (logical) CPUs (like cores, or hyper-threaded processors) available, i.e. seen by the operating system, and to add up the results of each run.
This procedure is similar to the “rate” metric of the SPEC CPU2006 benchmark suite. However, the parallel tasks are running totally independent from each other, while the tasks of a “rate” run are synchronised by the runspec tool provided by SPEC.
The advantage of the “parallel” metric of HS06 is that it exactly simulates the behavior of the batch system (LRMS) which tries to keep all job slots busy, i.e. immediately starts the next available queued job whenever a job has finished.
Some modern processors, e.g. the current Intel Xeon chips, provide hyper-threaded CPUs. If the “Symmentric Multi-Threading (SMT)” feature (Hyper-Threading) is enabled in the BIOS of the system, then the operating system sees twice as many computing units. It is mandatory to run the benchmark with exactly the same BIOS settings which are used in production mode!
Note: It is assumed that by default as many job slots are configured in the LRMS as CPUs are detected by the operating system (/proc/cpuinfo). If you have configured the number of job slots not equal to the real number of CPUs, then run HS06 with the number of parallel benchmark copies according to the number of job slots.
32-bit binaries
Run the benchmark with 32-bit binaries. The linux32-gcc_cern.cfg config file (coming with spec2k6-#.##.tar.gz archive) provides the appropiate settings and portability flags.
Before you start
Go and see for yourself that the system under test is idle and not occupied by another job or benchmark task! Check with other users that nobody else will run any task on the same machine while your benchmark is running!
You can disable user logins by adding an appropriate message to the /etc/nologin file. (Note that this file is only writable by root.)
The runspec.sh run script
The simplest way to run the benchmark is to use the runspec.sh script from the archive. Usage:
runspec.sh -h
To run the benchmark:
runspec.sh -d "HS06 32-bit" -a 32 -b all_cpp -e your.email@address.com
The script looks for an archive file CPU2006_v12.tar.bz2 of the SPEC CPU2006 benchmark suite, installs and runs the benchmark, and creates a results summary.
When you use the script for the first time, you have to create the SPEC CPU2006 tarball:
mkdir /mnt/SPEC2006_v12
mount -o ro /dev/cdrom /mnt/SPEC2006_v12
cd /mnt/
chmod -R u+w SPEC2006_v12
tar cvjf /SPEC2006_v12.tar.bz2 SPEC2006_v12
cd
umount /mnt/SPEC2006_v12 ; rmdir /mnt/SPEC2006_v12
( is the directory used for benchmarking.)
The advantage of this tarball-based installation, instead of using the original DVD from SPEC, is the possibility to launch the benchmark from batch jobs, without having to check for the worker node the job is running on and then to walk to that node to insert the DVD
(Some sites have already introduced the benchmarking as one part of the acceptance tests which they run on all newly delivered batches of machines.)
You can run the benchmarks from every user account. However, the runspec.sh script collects some information about the system under test. For instance, the dmidecode command which is launched to report hardware details. This command requires root access and doesn’t work for non-root users.
Manually installing the SPEC CPU2006 benchmark suite and running the HS06
If you don’t want to use that script, you can proceed with the instructions below. Note that all commands can run without root permissions:
-
Install the SPEC CPU2006 benchmarks using the install.sh script coming with the benchmark package. See either the Docs folder of the benchmark DVD or the SPEC CPU2006 web site for more detailed technical documents and HOWTOs.
-
Copy the linux32-gcc_cern.cfg config file from the spec2k6-#.##.tar.gz archive into the /config subfolder. Here is the directory where you have installed the SPEC CPU2006 benchmark suite:
cp linux32-gcc_cern.cfg /config -
Change the current working directory to . Source the /shrc script in order to adapt your user environment:
cd . shrc -
The SPEC CPU2006 benchmark suite is distributed as source. To be able to run the benchmark, you have to make the appropriate set of executables:
runspec --config=linux32-gcc_cern --action=scrub all_cpp runspec --config=linux32-gcc_cern --action=build all_cpp -
Run one copy of the benchmark per logical CPU (core, or hyper-threaded processor) which is seen by the operating system of the system under test. (If the number of job slots is different from the number of logical CPUs then run as many benchmark copies as there are job slots used by the batch system.) Note that it is mandatory to use exactly the same BIOS settings (for instance, Hyper-Threading or similar hardware features if available) which are also used in production mode:
n_cpus=4 # n_cpus=[number of job slots if different] for i in ; do ( runspec --config linux32-gcc_cern --nobuild --noreportable all_cpp & ) done wait -
Now you have plenty of time e.g. to join a bunch of meetings …
-
When all tasks of the benchmark are finished, you will find a lot of result files named CFP2006.###.ref.txt and CINT2006.###.ref.txt in the /result folder. The number of output files depends on the number of parallel benchmark runs, i.e. the number of cores in the system under test. For instance, if you run the benchmark on a dual socket quad-core processor machine, you will find the ouptut files CFP2006.003.ref.txt, …, CFP2006.010.ref.txt, and CINT2006.003.ref.txt, …, CINT2006.010.ref.txt.
-
The all_cpp benchmark subset of SPEC CPU2006 contains all the C++ benchmarks from CPU2006: 444.namd, 447.dealII, 450.soplex, 453.povray, 471.omnetpp, 473.astar, and 483.xalancbmk. The first mentioned four packages (444, 447, 450, and 453) are floating point benchmarks. The benchmark results are summarized in the CFP2006.###.ref.txt files. The remaining (471, 473, and 483) are integer benchmarks and print their results into the CINT2006.###.ref.txt files.
-
The benchmark script runs three iterations of each benchmark. The median of the three runs is selected to be part of the overall metric. In the results files (CFP2006.###.ref.txt and CINT2006.###.ref.txt), the medians are marked with an asterisk. This is an example:
grep "* *$" result/*.003.ref.txt | sort -u result/CFP2006.003.ref.txt:444.namd 8020 739 10.9 * result/CFP2006.003.ref.txt:447.dealII 11440 830 13.8 * result/CFP2006.003.ref.txt:450.soplex 8340 1577 5.29 * result/CFP2006.003.ref.txt:453.povray 5320 467 11.4 * result/CINT2006.003.ref.txt:471.omnetpp 6250 1032 6.06 * result/CINT2006.003.ref.txt:473.astar 7020 985 7.13 * result/CINT2006.003.ref.txt:483.xalancbmk 6900 914 7.55 * -
(Important note: there is a single whitespace between the two asterisks in the ‘grep’ pattern, not a tab sign!)
-
To calculate the score for each core of the system under test, compute the geometric mean of the seven C++ benchmarks, here shown with the numbers from the example above:
echo "scale=2 ; e((l(10.9)+l(13.8)+l(5.29)+l(11.4)+l(6.06)+l(7.13)+l(7.55))/7)" | bc -l 8.33 -
In the example, the performance of that particular core is about 8.33 HS06.
-
Repeat these steps for the remaining result files.
-
Sum up the results for each of the parallel runs to calculate the total HS06 score for the machine.
-
And last not least: sum up the HS06 score of each machine to compute the total amount of HS06 scores provided by your site.
Unlock the system under test when you have finished
If you have locked the machine while you were running the benchmark, don’t forget to remove the /etc/nologin file to enable logins by other users!
##= How to contribute to the results tables =
At least the LCG T1 sites are invited to contribute to the results table. Please, provide these information:
CPU type
grep "^model name" /proc/cpuinfo
This command prints something like ‘Intel(R) Xeon(R) CPU L5420 @ 2.50GHz’ or ‘Quad-Core AMD Opteron(tm) Processor 2376’. Please, shorten the output to a reasonable string, i.e. ‘Intel Xeon L5420’ or ‘AMD Opteron 2376’.
Don’t remove the version string of latest Intel chips. For instance, an ‘Intel Xeon E5-2670’ is an 8-core Sandy Bridge (32 micron) processor running at 2.6 GHz while an ‘Intel Xeon E5-2670 v2’ is a 10-core Ivy Bridge (22 micron) chip running at 2.5 GHz.
HS06
This is the total score of the system under test, i.e. the sum of the scores for each parallel run, as described above.
Clock speed (MHz)
grep "^cpu MHz" /proc/cpuinfo
L2 cache size (KB)
grep "^cache size" /proc/cpuinfo
Note that some processors share the L2 cache between cores. Other processors provide a separate L2 cache per core.
Cores (runs)
This is the number of cores (logical processors) on the system under test. You should have run one benchmark copy per core in parallel as described above.
grep -c "^processor" /proc/cpuinfo
Memory (GB)
The performance of a system can significantly depend on the memory, e.g., the number and also the type of the modules used.
To determine the total amount of memory:
free -m | grep ^Mem: | tr -s " " | cut -d " " -f 2
Note that a small amount of the installed memory is occupied by the graphics device and not available to the operating system. To convert MB to GB, divide that number by 1024 and round up to the next integer.
You can also login as root and run the ‘dmidecode’ command which reports the total size of the memory which is physically installed:
dmidecode
Search for the string ‘Memory Device’. You will find the total size and type details of the memory module. This information is available once per memory slot which is available on the mainboard. In order to compute the total amount of RAM, sum up the size of each memory module.
Don’t trust the indicated speed!
Mainboard type
Login as root and run the ‘dmidecode’ command:
dmidecode
The manufacturer of the mainboard, and the product name, are indicated in the ‘Base Board Information’ section of the output.
Script to automatize the system disclosure
A script to automatize these steps has been integrated into the spec2k6 tarball (release 2.23 or later). The simplest way is to run the runspec.sh script with the “-w” flag set. If you have already finished your benchmark runs, you can also run the script by hand:
./hepspec-systeminfo.sh 12.34
where “12.34” is just a placeholder for the HS06 score of this system. If you don’t want to run the hepspec-systeminfo.sh script as root, provide a file named “dmidecode-output” in the current working directory which contains the output of the dmidecode command. Be aware that on some machines the dmidecode command prints numbers which are wrong or misleading. Please, carefully check the results!
Adding results to WIKI
Please send the benchmark score and the hardware details of the system under test (output of ‘hepspec-systeminfo.sh’ command preferred), the file ‘/proc/cpuinfo’, the output of the ‘dmidecode’ command, and the tar’ed /result folder, to manfred.alef@kit.edu.
Thank you in advance!
##= Frequently asked questions (copied from twiki.cern.ch) =
Why don’t you just use the results from spec.org?
Those results aren’t representative of our environment or applications. Companies that submit scores to spec.org are interested in showing off how fast their machines are, so they use compilers like ICC, heavy optimizations, and optimized libraries to get the most performance. On the other hand, we’re interested in making sure our applications run on a wide variety of machines, so we use GCC and a predefined set of compilation flags chosen to match the running conditions used by the experiments. The numbers published on spec.org are nearly useless when it comes to comparing two different machines because the setups are usually very different. As for comparing them to our applications, they have some value as an estimator but they’re certainly not very precise.
Ok, but isn’t there a conversion factor between spec.org numbers and HS06?
No, there isn’t. SPEC doesn’t provide all_cpp results, so there’s nothing to convert from. The best you can do is assume that if machine A has a higher SPECint2006 number than machine B, it will probably also have a higher HS06 number, but not necessarily in the same proportion.
Why do you use those compilation flags? We could get more performance with other flags.
We use -O2 -fPIC -pthread -m32 because those are the flags mandated by the LCG Architect’s Forum. These are supposed to be the common flags used by the experiments when they compile their software. Again, the point is to have a benchmark that represents our applications, not to get the highest number possible.
If your OS is 64 bit, why do you run 32-bit binaries?
If our production machines run Linux x86_64, we use this OS for the benchmark as well - we want the benchmark to be representative of the real world. However, the applications are usually compiled in 32-bit mode, because that’s the recommendation of the LCG Architect’s Forum. Again, we want the benchmark to be as close as possible to the application.
Why do you use “multiple speed” instead of speed or rate?
The SPECcpu speed benchmark runs a single copy of the benchmark on the machine, using only a single core. The SPEC rate benchmark runs as many benchmarks as there are cores, but it calculates the results as a function of the total elapsed time. This skews the results, as a single slow core can keep the others idle until it finishes. Take a look at this graphical explanation of the difference between SPECcpu rate and multiple SPECcpu speed:
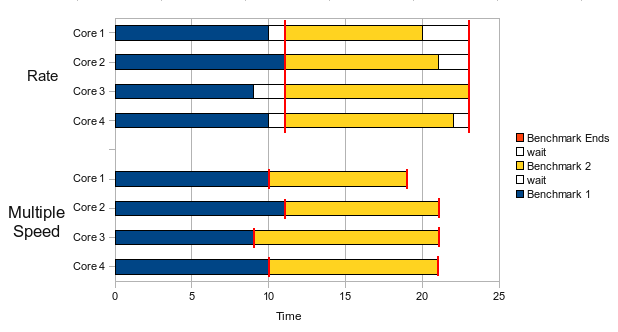
To overcome these problems, we decided to run multiple speed benchmarks in parallel. We launch one independent speed benchmark for each core in the system and then add up the results to come up with a total result for the system. This mimics what we do in our production environment, where we run multiple independent single-threaded applications in parallel.
Why do you use “all_cpp” instead of SPECint or SPECfp?
In general, our applications have a much higher percentage of integer operations than floating point. We’ve found that SPECint scales better with our application performance than SPECfp. However, SPECint2006 has a lower percentage of floating point than SPECint2000 (0.1% vs. 1%), and it doesn’t seem fair to completely ignore the floating point bit. During our investigations, we found that all_cpp was a very good match for the percentage of floating point operations we observed in lxbatch (~10%) and it still maintained the same scaling behavior with experiment code, so it is the most representative benchmark for our workloads. Similarly, a number of other quantities such as cache misses (indicating rate of memory accesses) have been shown to be better represented in SPEC CPU2006 benchmark set “all_cpp” than in SPECint or SPECfp.
Why don’t you just write your own benchmark suite?
While this would be the best way of measuring the performance we’re going to get out of the machines, it is just too difficult to do. Experiment code changes very frequently and we don’t have the man-power to create and support benchmarks from the different experiments. Additionally, this would probably be harder for vendors to execute, as experiment code generally has more dependencies. We found that the best solution was to take an industry-standard benchmark like SPECcpu2006 and “configure” it for our needs.