How to Run HEPScore23 Benchmark
- Requirements
- Run the HEP Benchmark Suite
- Run HEPScore23 standalone
- How to open a GGUS ticket
- Troubleshooting
This document provides instructions on how to execute the HEPScore23 benchmark.
Update 28 March 2025: A new version of the Hep Benchmark Suite, v3.0, has been released and will be used going forward. For more details, continue to read.
Requirements
It is crucial that the server is fully dedicated to the benchmarking activity during the run, to ensure accurate measurements and prevent potential errors.
The server must have a minimum hardware configuration (see requirements below) and include the following packages:
- Container engine Apptainer (version 1.1.6 or higher);
- Python version 3.9 or higher;
- python3-pip;
- git
The user will need pip and git to install HEPScore23 as a Python package.
Hardware requirements:
- A disk space proportional to the number of available cores on the server (about 1 GB per logical core) is necessary to temporarily store the results;
- The server must have at least 2GB of RAM per logical core;
- ulimit configuration (see details below)
Run the HEP Benchmark Suite
While it is possible to install HEPScore23 standalone (see later), it is recommended to use the HEP Benchmark Suite alongside HEPScore23 to include in the benchmark report metadata about the server’s running conditions. The metadata includes details about the server’s CPU, RAM, disks, IP addresses, and other relevant information.
Update 28 March 2025: Starting from version 3.0, the Suite includes plugins to extend functionality, such as power consumption, system load and memory usage monitoring. More details about these plugins can be found here.
The HEP Benchmark Suite can be installed using pip and git.
A bash script has been developed to streamline the installation and running process. This script provides a fully comprehensive running procedure and enables the system administrator to install the HEP Benchmark Suite and HEPScore23, run the HEP Benchmark Suite, which in turn extracts the necessary metadata from the server, executes HEPScore23 and produces a final output document.
Update 28 March 2025: The script is now updated to default to version 3.0 of the suite. It comes with default plugins (CPU frequency, system load, memory usage, memory swap, power consumption) included in the data collection. To take advantage of these updates, simply re-download and run the deployment script.
The script parameters can be consulted by running:
./run_HEPscore.sh -h
Script mandatory parameters
To use the bash script, users will need to provide a mandatory custom parameter to declare the specific site on which the benchmark is running.
The SITE parameter is essential for ensuring that the results are accurately attributed to the correct site when integrated into the WLCG Benchmark DB. If the “SITE” parameter cannot be assigned or the user opts not to declare it, a dummy value like “dummy” or “anonymous” should be used as a placeholder. These placeholder values avoid that the script raises exceptions, and allow, in case of publication, for the integration of data into the database while indicating that the site information is intentionally omitted.
To run the script, users can use the following command line.
./run_HEPscore.sh -s SITE
By default, the script will use the current directory to create a working directory where all necessary files will be stored, including container images, benchmark outputs, and temporary workload results. The working directory can be modified using the parameter -d target_folder.
During the execution the script reports the stdout of the HEP Benchmark Suite. If the execution completes successfully, it will print at the end information such as
[INFO] Successfully completed all requested benchmarks
=========================================================
BENCHMARK RESULTS FOR <hostname>
=========================================================
Suite start: start_date
Suite end: end_date
Machine CPU Model: name
HEPscore Benchmark = value
Using the bash script ensures that the entire process is performed correctly, and it is recommended that users utilize it when installing and running HEPScore23.
Configuring Usage Metering Plugins
To customize the time series monitoring plugins, use the -b plugin_keys parameter. The following keys are available:
- f - CPU frequency
- l - System load
- m - Memory usage
- s - Memory swap
- p - Power consumption
- g - GPU power consumption
- u - GPU usage
By default, the following plugins are enabled: f,l,m,s,p. To disable all plugins, use -b none.
Publish results (Optional)
The HEP Benchmark Suite also offers the added benefit of being able to submit the benchmark results to the WLCG Benchmark DB (based on OpenSearch/ElasticSearch). To accomplish this, a valid X509 certificate (service, robot, user) must be available, and the certificate’s DN must be authorized for the publication of the results.
The command line options of the script will include the -p (publish) argument, as well as the mandatory certificate and key file location.
To run the script, users can use the following command line.
./run_HEPscore.sh -s SITE -p -c /path/to/cert.pem -k /path/to/key.pem
To declare the DN users should open a GGUS tickets. For additional information please refer to the below section.
DN extraction
To extract the DN from the certificate run:
openssl x509 -noout -in user.crt.pem -subject -nameopt RFC2253
which should output something similar to:
subject=CN=Name Surname,CN=123456,CN=username,OU=Users,OU=Organic Units,DC=cern,DC=ch
Run HEPScore23 standalone
If the usage of the HEP Benchmark Suite and the orchestrator bash script is not an option for you, the following instructions will allow the installation of the python package of HEPScore23. It is recommended to use a virtual environment to install HEPScore23.
python3 -m venv HS23env
source HS23env/bin/activate
pip3 install git+https://gitlab.cern.ch/hep-benchmarks/hep-score.git@v1.5
- to access the help menu
hepscore -h - to dump the HEPScore23 configuration
hepscore -p - to run
hepscore -v /path/to/workdir
How to open a GGUS ticket
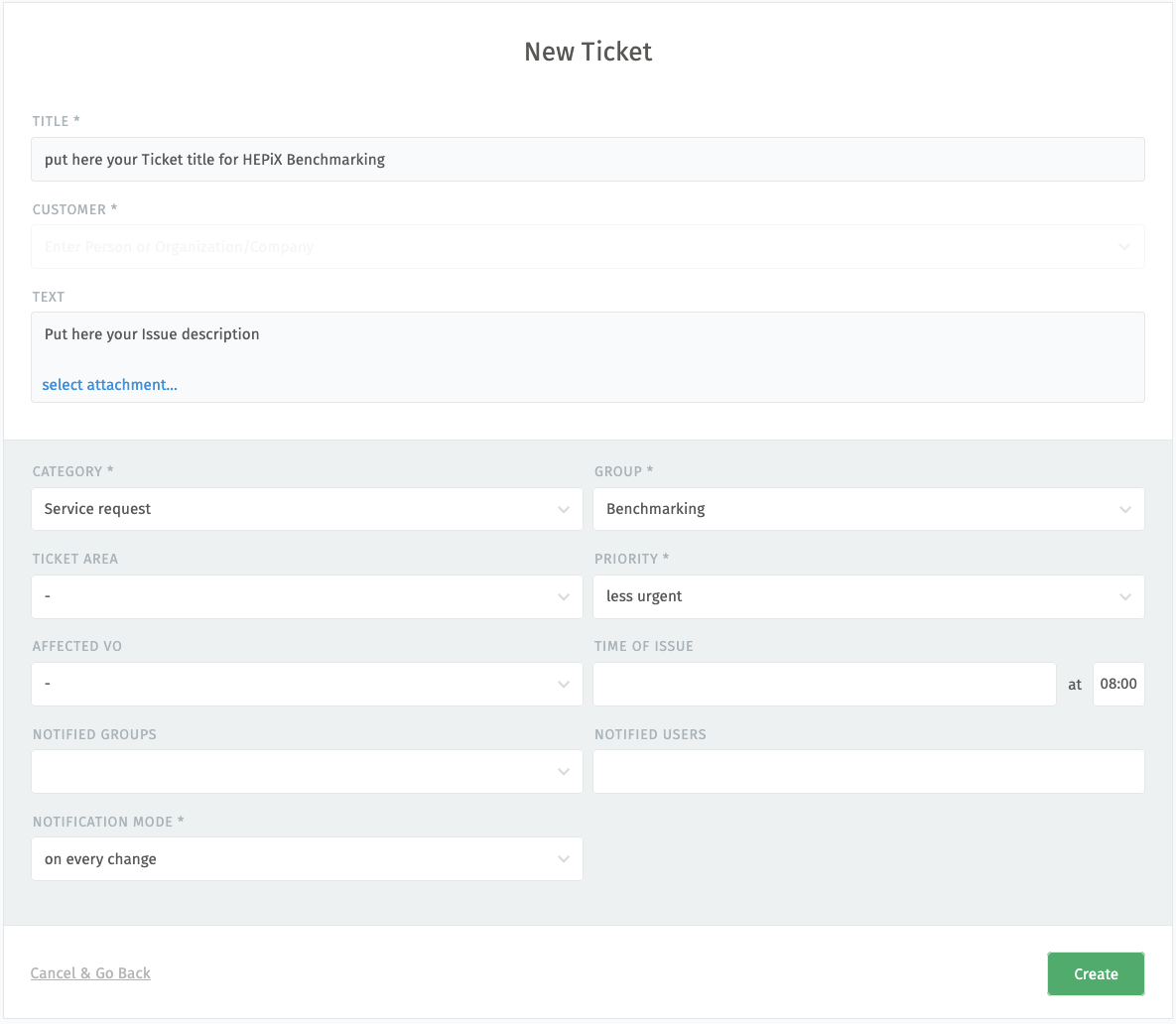
If assistance is needed, the support unit of HEPscore can be reached via GGUS tickets. In that case the Group to be selected is Benchmarking and the Category is Service request , as in the screenshot here:
Troubleshooting
ulimit configuration on CENTOS7 (reason and procedure)
A workload of the HEPScore23 benchmark uses a multi-service approach for the reconstruction and starts multiple processes per core that stay idle waiting for their turn of processing. For machines with more than 100 CPU cores, this translates into more than 4096 processes, which is the default for normal (non-root) users on CentOS7. Therefore, HEPScore23 should run as root, or the user should be able to start more processes. This can be set with ulimit on CentOS7 by adding the line
echo "benchmark soft nproc unlimited" >> /etc/security/limits.d/20-nproc.conf
It is necessary to start a new shell session after that change before running HEPScore23.
CVMFS (as image repository) configuration
Although it’s not part of the standard configuration, it is possible to get the container images for the benchmark from CVMFS instead of from the gitlab registry. Be aware that the resulting score is reduced by about 5% using the CVMFS registry since CVMFS needs some CPU resources.
Some workloads of the HEPScore23 benchmark access several files in parallel on /cvmfs, which results in failing benchmarks on big machines (more than 60 cores). Therefore, please enable CVMFS_CACHE_REFCOUNT = yes in /etc/cvmfs/default.local released in CVMFS version 2.11.0. Otherwise, it is necessary to adjust the CVMFS config and set the maximal number of open files (CVMFS_NFILES in /etc/cvmfs/default.local) value to about 200 times the number of cores. The new value is active after a remount of the CVMFS repository on the machine.